How to Rank SaaS Ideas Before Building
If you are a technically capable solo founder, Cursor, Claude Code, Lovable, Bolt, v0, ChatGPT, and Claude can make several SaaS ideas feel buildable at the same time. That is useful, but it also creates a new failure mode: choosing the newest, easiest, or most emotionally appealing idea instead of the one with the best evidence path.
To rank SaaS ideas, use the same input standard, the same rubric, and the same evidence standard for every idea. A ranking process should not tell you which idea is guaranteed to win. It should tell you which idea deserves the next serious validation cycle.
To rank SaaS ideas before building, refine every idea to the same level of detail, score each idea with the same weighted SaaS rubric, sort by weighted score, check disqualifiers and weak dimensions, apply founder-fit and evidence-speed tiebreakers, then choose the next validation step. The top-ranked idea is not proven; it is the idea that deserves the next evidence cycle.
This article uses Genhone's SaaS idea scoring framework as the deeper rubric behind the process. The boundary matters: ranking is decision support, not proof of demand, product-market fit, revenue, willingness to pay, or startup success.
What It Means to Rank SaaS Ideas
Ranking SaaS ideas means creating an ordered list of which ideas deserve the next evidence cycle. It is not brainstorming. It is not validating one idea. It is not founder therapy. And it is not picking the idea that sounds most exciting in a chat thread.
A useful ranking output should show:
- the ordered list of ideas
- the reasoning behind the order
- the weakest dimension for each idea
- any disqualifiers
- the founder-fit and evidence-speed tiebreakers
- the next action for each idea
That last point is the real goal. The top-ranked idea should usually receive the next customer discovery cycle, pricing test, concierge test, landing page test, or narrow MVP test. It should not automatically become a full product build.
If you have only one idea, start with how to validate a SaaS idea before building. If you have several ideas, rank them only after each one is specific enough to score with the same SaaS idea scoring framework.
| Term | What it means | What this article should say |
|---|---|---|
| Scoring | Assigning criteria-level and weighted scores to one idea. | Use the scoring framework for the rubric. |
| Comparing | Looking at several ideas side by side. | Comparison makes differences visible. |
| Ranking | Ordering ideas by score, risk pattern, founder fit, and evidence speed. | Ranking chooses the next evidence cycle. |
| Validating | Collecting buyer evidence that changes the decision. | Ranking should lead into validation, not replace it. |
A practical ranking workflow looks like this:
| Step | Input | Output |
|---|---|---|
| Make ideas comparable | Rough ideas, notes, chats, and assumptions | Same-shaped idea snapshots |
| Score with one rubric | Comparable snapshots | Weighted scores and criteria-level reasoning |
| Sort the ideas | Weighted totals | First-pass rank order |
| Check disqualifiers | Weak dimensions and severe risks | Ideas to narrow, park, kill, or test |
| Apply tiebreakers | Founder fit and evidence speed | Practical final ranking |
| Choose the next cycle | Highest-leverage uncertainty | Customer, pricing, channel, scope, or founder-fit test |
Step 1: Make Every SaaS Idea Comparable
Ranking fails when one idea is a polished pitch and another is still a rough sentence. The polished idea looks more mature because it has more detail. The vague idea can also look better because it still contains every imagined version of the product.
Before ranking, each idea needs a comparable snapshot. Structured strategy tools such as Strategyzer's Business Model Canvas show the value of giving every business model the same fields. For SaaS idea ranking, Genhone uses a more specific 12-section refinement model for solo founders.
Those 12 sections are:
- Idea Essence
- Problem Definition
- Solution Mechanics
- Customer Definition
- Value Proposition
- Business Model
- Technical Foundation
- Go-to-Market Approach
- Customer Onboarding & Activation
- Key Metrics Framework
- Scope & Boundaries
- Solo Founder Execution
These sections are not paperwork. They make the ranking fair.
If Idea A has a defined buyer, pricing model, MVP scope, channel, and solo-founder constraint while Idea B is "AI for accountants," the ranking is already biased. You are not comparing ideas. You are comparing one artifact against one wish.
The Customer Definition section is especially important. If you cannot name the first buyer, where they gather, what tools they use, and why the problem hurts now, go back and define the ICP for a SaaS idea before scoring. If the whole idea still feels incomplete, a SaaS idea validation checklist can expose the missing pieces before you create a startup idea scorecard.
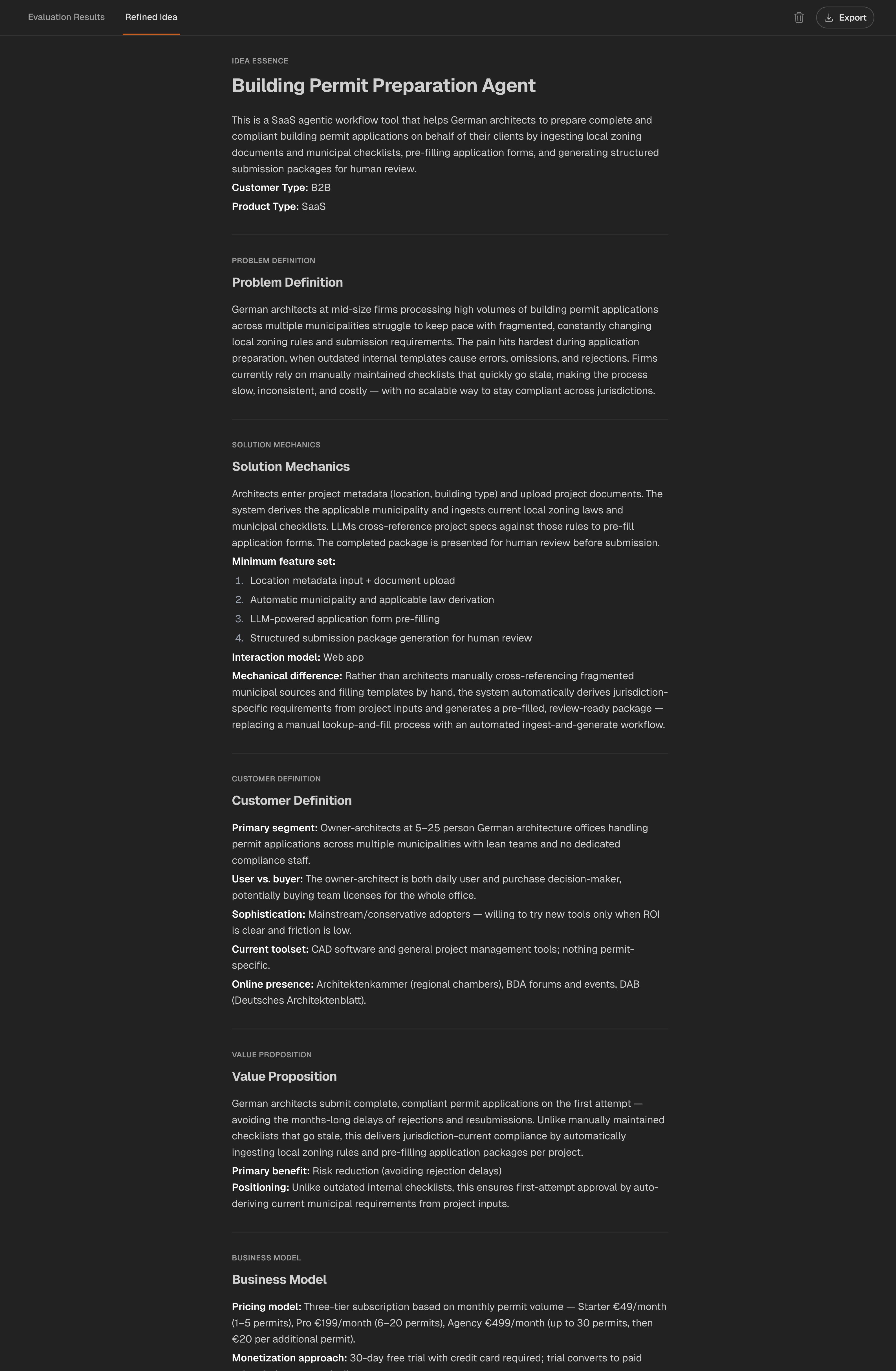
Step 2: Score Every Idea With the Same SaaS Rubric
A ranking order needs the same rubric for every idea. Otherwise, the idea with the most convenient assumptions wins.
Genhone scores SaaS ideas across 18 criteria in 5 weighted dimensions. The goal here is not to re-teach the full 18-criterion model, but to use it as the common measurement system for ranking.
Genhone starts with 12-section structured refinement, evaluates each SaaS idea across 18 criteria in 5 weighted dimensions, combines direct automated scoring with research-assisted automated scoring where market context matters, uses founder conversation for criteria that require firsthand founder context, and saves the result as a comparable idea artifact. The score is not a prediction and cannot replace buyer evidence.
The current scoring model uses 13 automated criteria total: 8 direct automated criteria scored from the refined idea and 5 research-assisted automated criteria where market context matters. The remaining 5 founder-conversation criteria require firsthand founder input: Problem Criticality, Willingness to Pay, Technical Skill Match, Personal Interest, and Operational Complexity.
| Dimension | Weight | Criteria | Ranking question |
|---|---|---|---|
| Problem Validation & Market Demand | 30% | Problem Criticality, Market Size, Willingness to Pay | Which idea has the strongest painful buyer problem and payment logic worth testing? |
| Technical Feasibility & Build Speed | 25% | Time to MVP, Technical Complexity, Technical Skill Match | Which idea can one founder build and operate fastest without fragile complexity? |
| Unit Economics & Monetization | 20% | CAC Expectations, Expected Churn, LTV Potential | Which idea has the most plausible path to recurring revenue and retention? |
| Go-to-Market Accessibility | 15% | Channel Accessibility, Organic Discovery, Sales Cycle Complexity | Which idea has reachable first users without a large team, ad budget, or long sales motion? |
| Founder Fit & Sustainability | 10% | Competitive Landscape, Personal Interest, Resource Requirements, Operational Complexity, Validation Speed, Time to Revenue | Which idea best fits this founder's constraints, stamina, resources, and learning speed? |
This structure keeps the ranking from overvaluing what is easiest to build. A solo founder can ship a simple product quickly and still choose a weak idea if buyer pain, payment logic, or channel access is soft.
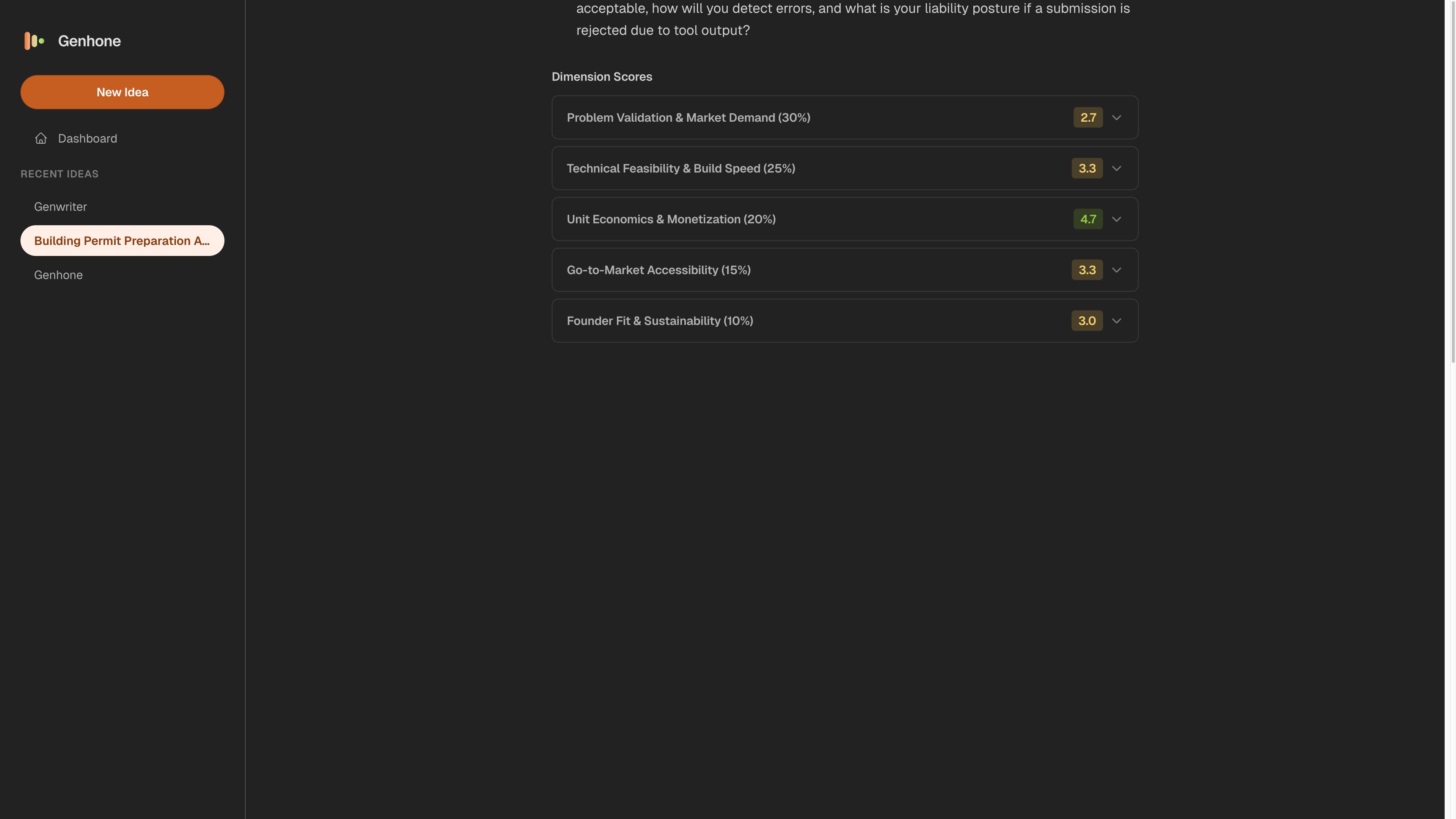
Step 3: Sort by Weighted Score, Then Inspect the Pattern
Start by sorting the ideas from highest weighted total to lowest. That gives you the first-pass ranking.
Use the score label as a shorthand, not as the whole decision. Genhone's current interpretation labels are:
| Weighted score | Label | Ranking meaning | Next action |
|---|---|---|---|
| 4.0-5.0 | Strong Opportunity | Rank near the top if no fatal dimension is weak. | Run the next smallest buyer-evidence test or tightly scoped MVP. |
| 3.0-3.99 | Promising | Often a top candidate if the weakness is fixable. | Fix the weakest dimension and collect better evidence before building. |
| 2.0-2.99 | Needs Work | Usually not a top-ranked idea in its current form. | Narrow buyer, problem, pricing, channel, or MVP boundary and rescore. |
| Below 2.0 | High Risk | Usually bottom-ranked unless new evidence changes the thesis. | Kill, archive, or restart from a stronger problem. |
The weighted score is the first pass, not the final answer. A high total can hide a weak dimension. A lower total can beat a higher total if its weakness is narrower, more fixable, and faster to test.
For example, a SaaS idea with strong technical feasibility and founder fit can still be a poor next build if willingness to pay is vague. Another idea with a lower total may deserve the next evidence cycle if the founder can talk to qualified buyers this week and test the riskiest assumption quickly.
Your ranking table should include more than the total score:
| Ranking field | Why it matters |
|---|---|
| Total score | Creates the first-pass order. |
| Label | Gives a quick interpretation of the score band. |
| Weakest dimension | Shows where the idea is most fragile. |
| Disqualifier status | Prevents a neat average from hiding a fatal weakness. |
| Tiebreaker result | Accounts for founder fit and evidence speed. |
| Next action | Turns the ranking into a validation decision. |
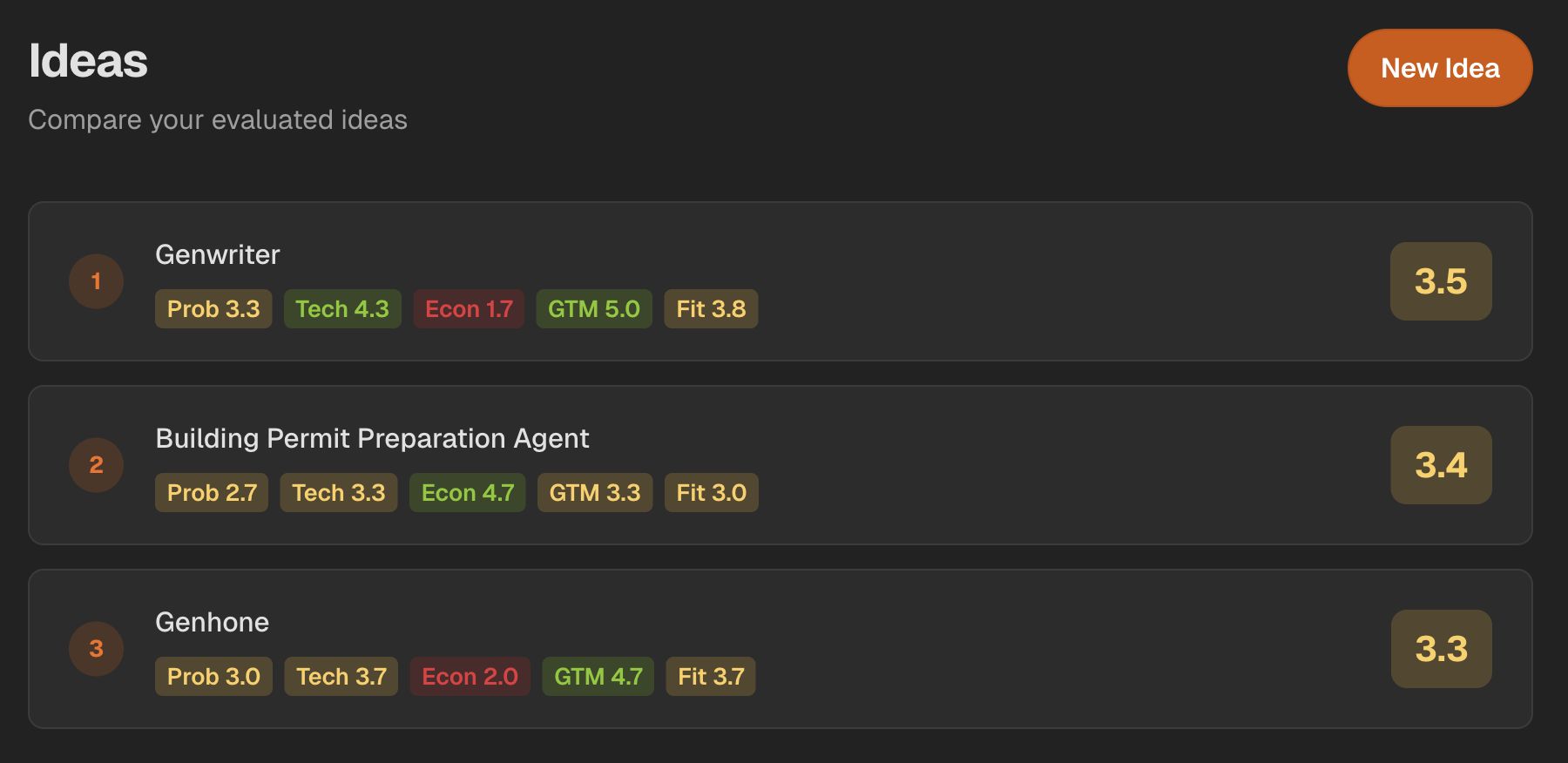
Step 4: Check Disqualifiers Before You Trust the Ranking
Disqualifiers are severe weaknesses that should override a neat average. In this context, "disqualifier" does not mean the idea is permanently dead. It means the idea is not worth the next build cycle in its current form.
This is where many ranking systems become too optimistic. They average a strong build path, a fun founder problem, and a vague buyer into a passable score. But weak pain or no payment path can break the whole thesis.
YC's Essential Startup Advice repeatedly points founders back to talking to users, focusing on painful problems, and avoiding premature scaling. Paul Graham's Do Things That Don't Scale supports the same early-stage lesson: manually recruit, learn from, and serve early users before pretending the system can scale.
Use disqualifiers to decide what gets down-ranked, narrowed, parked, or tested next. If competition or alternatives are unclear, run a SaaS competitor analysis before MVP instead of relying on a score.
| Disqualifier | What it looks like | Ranking impact | What to do next |
|---|---|---|---|
| Weak buyer pain | Users say it is interesting but cannot describe a painful current workflow. | Down-rank even if build feasibility is high. | Interview buyers or narrow to a more urgent workflow. |
| No willingness-to-pay path | No budget owner, current spend, economic pain, or plausible subscription value. | Down-rank or park. | Run pricing conversations or validate SaaS pricing before launch. |
| Unreachable first market | The buyer exists in theory but the founder cannot source conversations. | Down-rank below a more reachable idea. | Redefine ICP or choose a reachable beachhead. |
| Unrealistic solo build scope | MVP requires a platform, heavy compliance, brittle integrations, or a team. | Down-rank unless scope can be narrowed. | Cut to one workflow or one integration. |
| Inaccessible GTM | The idea needs enterprise sales, paid acquisition, or partnerships the founder cannot execute. | Down-rank even with strong demand. | Pick a lower-friction channel or buyer segment. |
| Poor founder fit | The founder lacks buyer access, technical match, patience, or support capacity. | Use as a tiebreaker or disqualifier. | Reassess founder-idea fit before building. |
| Slow evidence cycle | The idea requires a full product before meaningful learning. | Down-rank behind ideas that can be tested faster. | Design a smaller evidence test or park. |
The point is not to punish ideas for being imperfect. Every early idea is imperfect. The point is to avoid spending another build cycle on a weakness that should have been visible before code.
Step 5: Rank Weakest Dimensions, Not Just Ideas
After sorting by weighted score and checking disqualifiers, rank the weakest dimensions. Each idea should have a weakest dimension and a weakest assumption.
The practical question is not only "Which idea is strongest?" It is "Which weakness is most fixable and testable?"
Weakest-dimension analysis explains why a top-scoring idea might still not deserve the next build cycle. If the top idea has soft willingness to pay and the second idea has a narrower technical-scope problem, the second idea may be the better next evidence cycle. Scope can often be cut. Payment logic cannot be wished into existence.
| Weakest dimension | What it means | Ranking interpretation | Next evidence cycle |
|---|---|---|---|
| Problem Validation & Market Demand | Pain, market, or payment logic is soft. | Do not build until buyer pain is clearer. | 10-15 buyer conversations, problem interviews, paid workaround research. |
| Technical Feasibility & Build Speed | Build path is slower or riskier than expected. | Rank below ideas with simpler first versions unless demand is much stronger. | Scope reduction, prototype risk spike, one-workflow MVP definition. |
| Unit Economics & Monetization | Revenue, retention, or acquisition payback looks weak. | Rank below ideas with better subscription logic. | Pricing test, current spend research, churn-risk analysis. |
| Go-to-Market Accessibility | Buyers are hard to reach. | Rank below ideas where first users are accessible. | ICP narrowing, channel test, community research. |
| Founder Fit & Sustainability | The idea may be good but wrong for this founder. | Use as a tiebreaker and possible disqualifier. | Founder-fit conversation, support-load check, buyer-access audit. |
This is also where weak ideas become useful. A poor ranking is not wasted work if it tells you what to kill, narrow, or revisit later. Use when to kill a startup idea when the weakness is structural. Use how to evaluate a SaaS idea before building when one idea needs deeper analysis before it belongs in a ranking set.
Step 6: Use Founder-Fit and Evidence-Speed Tiebreakers
Close scores should not be decided by decimals alone. A 3.72 and a 3.65 are not meaningfully different if the input evidence is still early. The practical ranking should account for founder fit and evidence speed.
Founder fit can change the order because the founder is the researcher, builder, seller, support function, and decision-maker. A market can be real while still being a poor next idea for this founder. Research experiments such as Founder-GPT show founder-idea fit is receiving attention as a concept, but that does not mean AI can predict startup success or replace founder judgment.
Evidence speed matters because ranking happens before building. Steve Blank's HBR article on why the lean startup changes everything frames startups as work under uncertainty, where hypotheses need customer development rather than static planning. In ranking terms, the better next idea is often the one where the riskiest assumption can be tested fastest.
| Tiebreaker | Choose the idea that... | Down-rank the idea that... |
|---|---|---|
| Buyer access | Lets the founder talk to qualified buyers immediately. | Has an attractive market but no reachable prospects. |
| Founder knowledge | Fits the founder's domain understanding and judgment. | Requires the founder to learn the market from zero. |
| Technical skill match | Can be built with the founder's current stack and skills. | Requires new infrastructure, compliance, or platform complexity. |
| Distribution path | Has one plausible first channel. | Depends on vague content, paid ads, or partnerships. |
| Support sustainability | Can be supported by one person early. | Turns into custom services or high-touch implementation. |
| Evidence speed | Can test the riskiest assumption in days or weeks. | Requires a full product before learning. |
A slightly lower-scoring idea can rank first if the founder can reach buyers this week, test payment interest, and narrow scope quickly. A higher-scoring idea can rank lower if it requires long sales cycles, heavy technical scope, or buyer access the founder does not have.
For a deeper treatment of this lens, use founder-idea fit before building a SaaS.
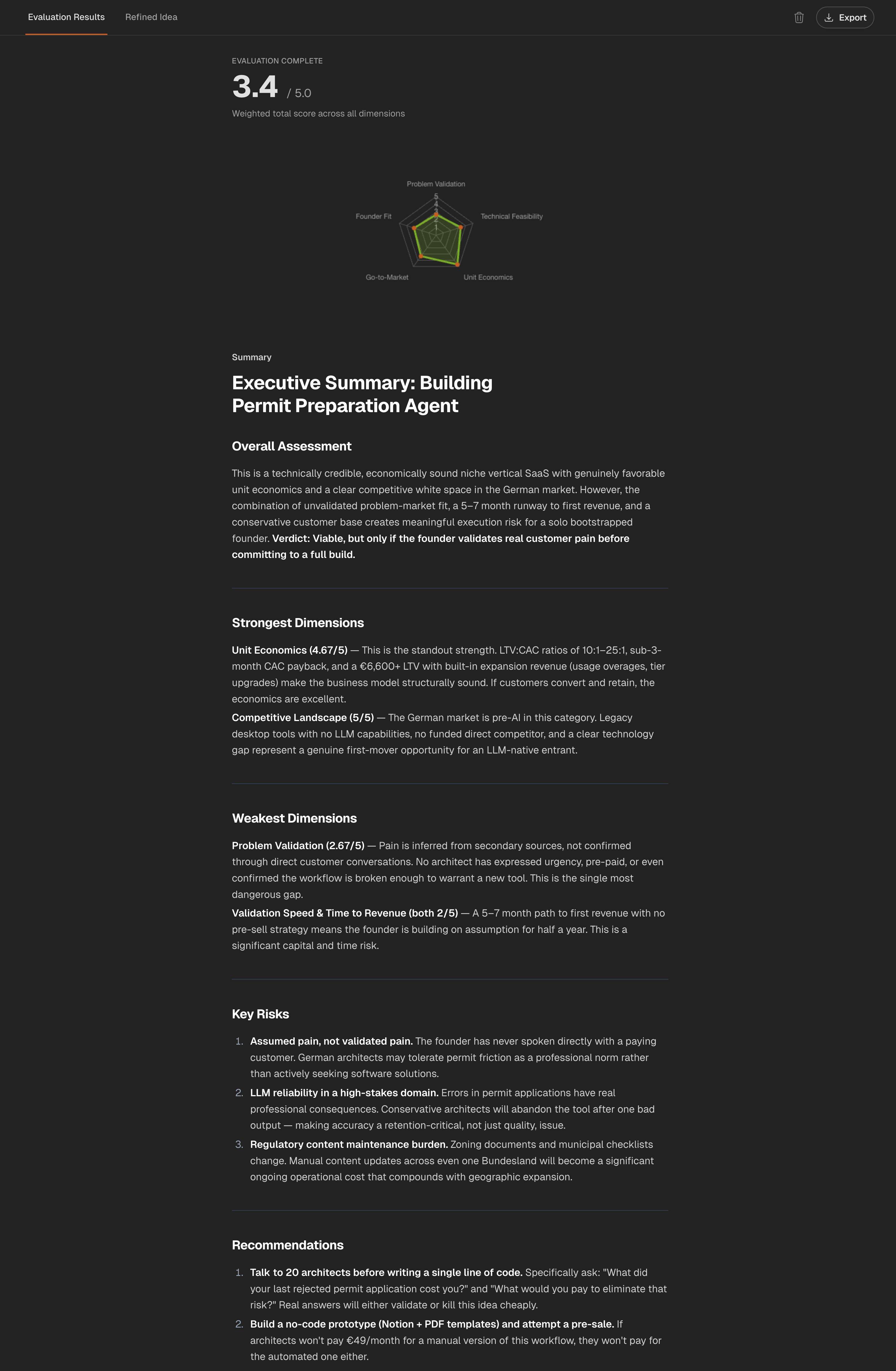
A Fictional Example: Ranking Three SaaS Ideas
This is a fictional example. These are not Genhone customer outcomes, proprietary benchmark scores, screenshots, or validation results.
Assume a solo founder is comparing three SaaS ideas:
- a building permit follow-up assistant for small construction firms
- a Shopify retention audit tool for a narrow segment of store operators
- AI meeting notes for all teams
The initial weighted sorting puts the Shopify retention audit tool and building permit follow-up assistant in the Promising range, while the broad AI meeting notes idea lands in Needs Work. The final ranking changes after disqualifiers and tiebreakers.
| Fictional idea | Weighted label | Weakest dimension | Disqualifier check | Tiebreaker result | Final rank | Next evidence cycle |
|---|---|---|---|---|---|---|
| Shopify retention audit tool | Promising | Willingness to Pay or Unit Economics | No fatal disqualifier if store segment is narrow. | Strong buyer access and fast evidence path. | 1 | Interview 10 Shopify operators in one narrow segment and test paid audit interest. |
| Building permit follow-up assistant | Promising | Go-to-Market Accessibility | Channel access is soft but fixable. | Strong problem specificity, slower buyer access. | 2 | Narrow to one permit workflow and source 8 buyer conversations. |
| AI meeting notes for all teams | Needs Work | Problem Validation & GTM | Broad market, saturated alternatives, weak wedge. | Easy to build but hard to rank high. | 3 | Kill or restart with a narrower buyer and sharper pain. |
The Shopify retention audit tool ranks first not because it is the broadest market or the most exciting product. It ranks first because the next evidence cycle is clear: talk to a narrow group of operators and test paid audit interest.
The building permit follow-up assistant may have a sharper workflow problem, but the founder needs to solve buyer access before it deserves the next build cycle.
The AI meeting notes idea is easy to start building, which is exactly the danger. A broad buyer, saturated alternatives, and weak wedge should push it down until the founder can name a more specific customer and painful workflow.
A startup idea scorecard gives each idea a comparable artifact. A broader guide on how to choose between startup ideas can help when the comparison is not SaaS-specific.
Turn rough SaaS ideas into scored, comparable artifacts with Genhone.
What to Do With the Top-Ranked SaaS Idea
The top-ranked idea earns the next evidence cycle. It does not earn an automatic full build.
That next action depends on the weakest dimension:
| Top-ranked idea status | What it means | Next action |
|---|---|---|
| Strong Opportunity with no fatal weakness | Coherent enough for the next focused test. | Run the smallest buyer-evidence test or tightly scoped MVP. |
| Promising with one fixable weakness | Good candidate, but not build-ready yet. | Fix or test the weak dimension first. |
| High total but fatal weakness | Average is hiding a serious risk. | Down-rank, narrow, or park until evidence changes. |
| Lower total but fast evidence path | May be the best next learning cycle. | Test the riskiest assumption quickly. |
A good evidence cycle defines six things:
| Evidence-cycle field | What to define |
|---|---|
| Buyer | The exact person or segment you will test with. |
| Assumption | The riskiest belief that must become clearer. |
| Evidence source | Interviews, pricing conversations, current spend research, channel test, concierge test, or narrow MVP. |
| Threshold | What would change your decision. |
| Time box | How long you will run the test before deciding. |
| Decision | Build narrower, keep testing, re-rank, park, or kill. |
Do not run all ideas in parallel unless you have unusually strong evidence and enough capacity. Parallel validation sounds efficient, but it usually creates shallow learning across too many weak assumptions. Pick the best next evidence cycle, run it, and re-rank when the evidence changes.
If ranking reveals several weak ideas, use when to kill a startup idea to decide what to archive, narrow, or revisit.
How Genhone Helps Rank SaaS Ideas Without Spreadsheets
This perspective comes from building Genhone for solo founders who use AI and agentic coding tools. The common failure pattern is not lack of build speed. It is building before the idea is clear enough to compare honestly.
Genhone turns rough SaaS ideas into structured, scored, saved artifacts:
- Guided 12-section refinement.
- 18-criterion evaluation across 5 weighted dimensions.
- 13 automated criteria.
- 5 founder-conversation criteria.
- Saved artifacts.
- Side-by-side comparison.
The current automated split is 8 direct automated criteria and 5 research-assisted automated criteria. Founder-conversation criteria cover the inputs that require firsthand context: Problem Criticality, Willingness to Pay, Technical Skill Match, Personal Interest, and Operational Complexity.
The mechanical difference from unstructured ChatGPT usage is consistency. You do not need to manually transfer idea notes into a spreadsheet, normalize fields, rebuild scorecards, or compare lost chat outputs. Each idea goes through the same refinement shape, the same scoring system, and the same saved artifact flow.
Genhone is still decision support. It does not prove demand, product-market fit, future revenue, or startup success. It helps a solo founder choose what to validate next before another AI-assisted build cycle turns a weak idea into sunk cost.
Turn rough SaaS ideas into scored, comparable artifacts with Genhone.
FAQ
What is the best way to rank SaaS ideas?
The best way to rank SaaS ideas is to refine every idea to the same level, score each one with the same SaaS-specific weighted rubric, sort by weighted score, check disqualifiers and weak dimensions, apply founder-fit and evidence-speed tiebreakers, then choose the next evidence cycle.
The ranking should produce an ordered list with reasoning and next actions, not just a score.
Should I build the SaaS idea with the highest score?
Not automatically. The highest-scoring SaaS idea earns attention only if no fatal dimension is weak.
The next step is usually a buyer-evidence test, pricing test, concierge test, landing page test, or tightly scoped MVP. A high score does not prove product-market fit, willingness to pay, retention, or future success.
How many SaaS ideas should I rank at once?
Three to five SaaS ideas is usually manageable. More than that creates comparison noise and makes it harder to inspect weak dimensions honestly.
If you have 10 or more ideas, use quick pass/fail gates first. Remove ideas with no specific buyer, weak pain, unrealistic solo scope, unreachable channels, or poor founder fit. Then rank the remaining candidates in more detail.
What if one SaaS idea has a high score but weak founder fit?
Down-rank it or pause it until the founder-fit concern is resolved. Strong market logic does not help if the founder cannot reach buyers, build the first useful version, support users, or stay engaged long enough to learn.
Founder fit is not the only factor, but it matters heavily for solo founders. Use founder-idea fit before building a SaaS when a high-scoring idea looks good in theory but wrong for your constraints.
Can AI rank SaaS ideas for me?
AI can help structure inputs, apply a rubric, summarize evidence, and expose weak assumptions. That can make ranking faster and more consistent.
AI cannot replace buyer conversations, payment behavior, current-workaround evidence, or founder honesty. Treat AI-assisted ranking as structured decision support, not predictive certainty.
Should I rank ideas before or after customer interviews?
Do a rough ranking before interviews so you know where to spend discovery effort first. Then re-rank after interviews when the evidence changes.
The ranking should be a living artifact. If buyer pain is weaker than expected, down-rank the idea. If willingness to pay becomes clearer, re-score it. If founder fit gets worse after you understand the support burden, change the order before building.